I did some benchmarks of my own today. Now disclaimer here, I’m rather busy at the moment with multiple projects on the go, so I leaned heavily on Claude Sonnet and Qwen Coder to pull these together.
I’m using the latest git versions of all frameworks as of today.
The benchmark borrows the zombies in @Matse’s demo, and on enter frame, inserts all 16 types of zombies repeatedly until the framerate over the last 120 frames, averages below 55fps at which point it stops adding zombies.
I had hoped to include @rainy’s HXMaker framework, but I was having some difficulties with dependencies.
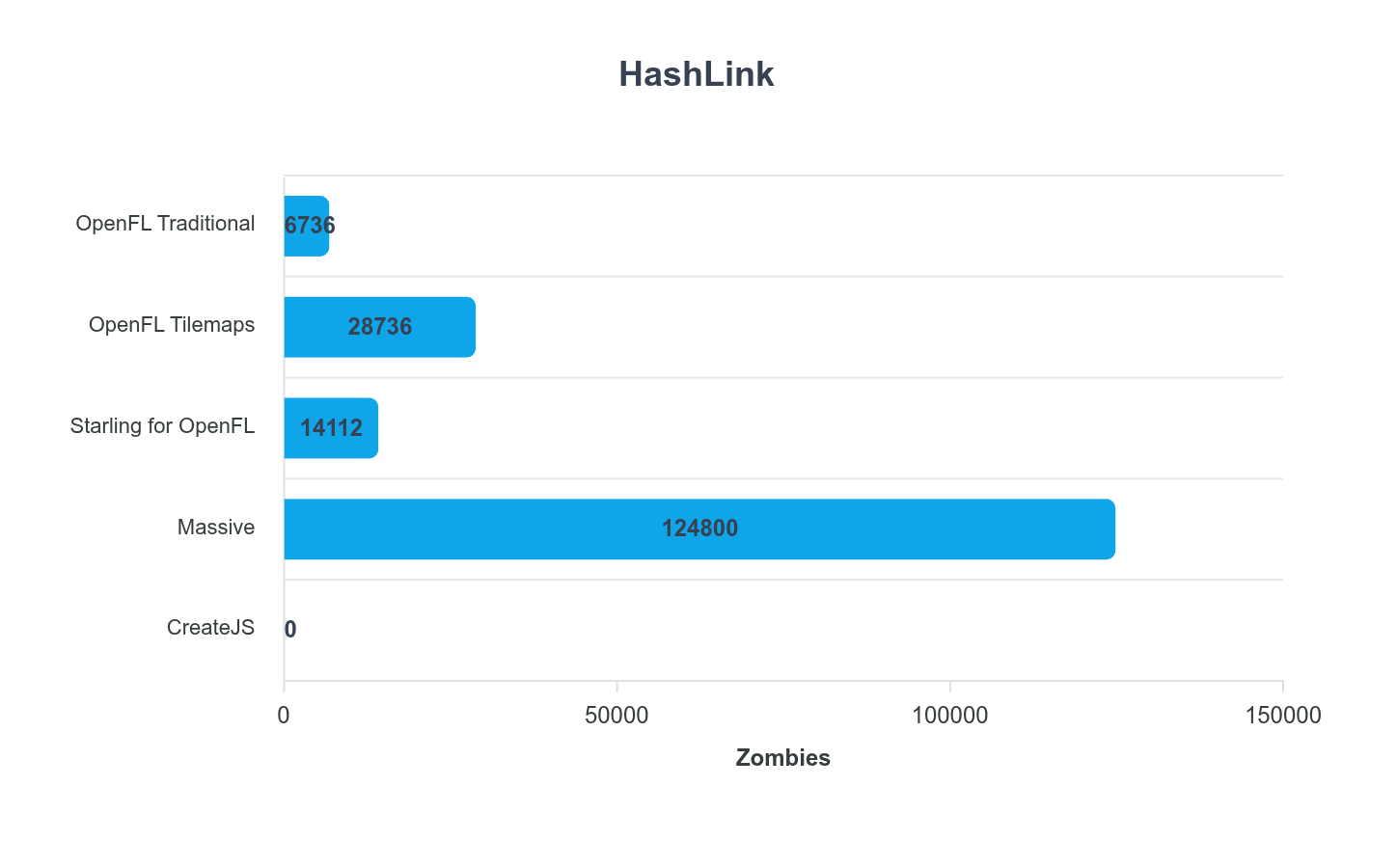
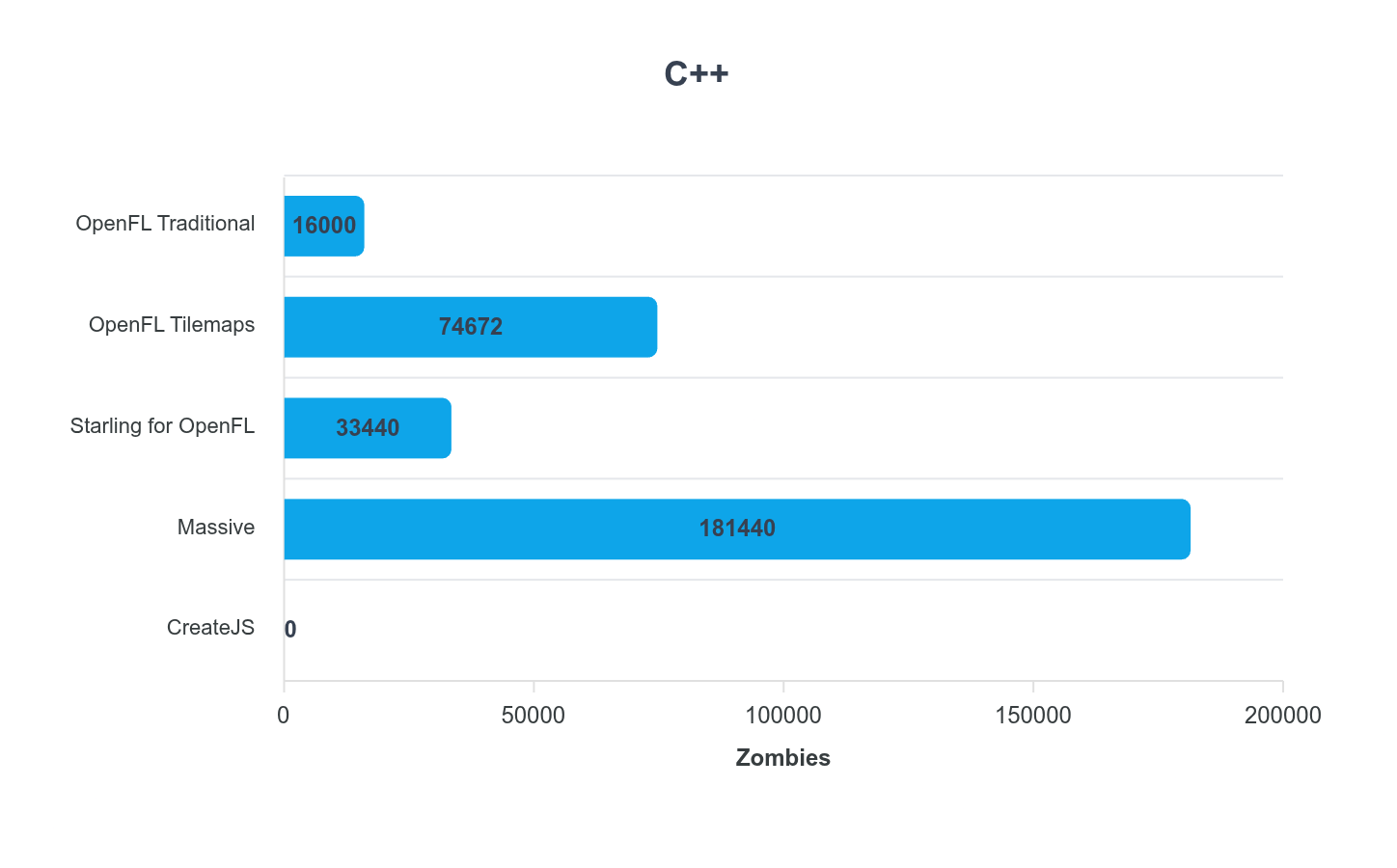
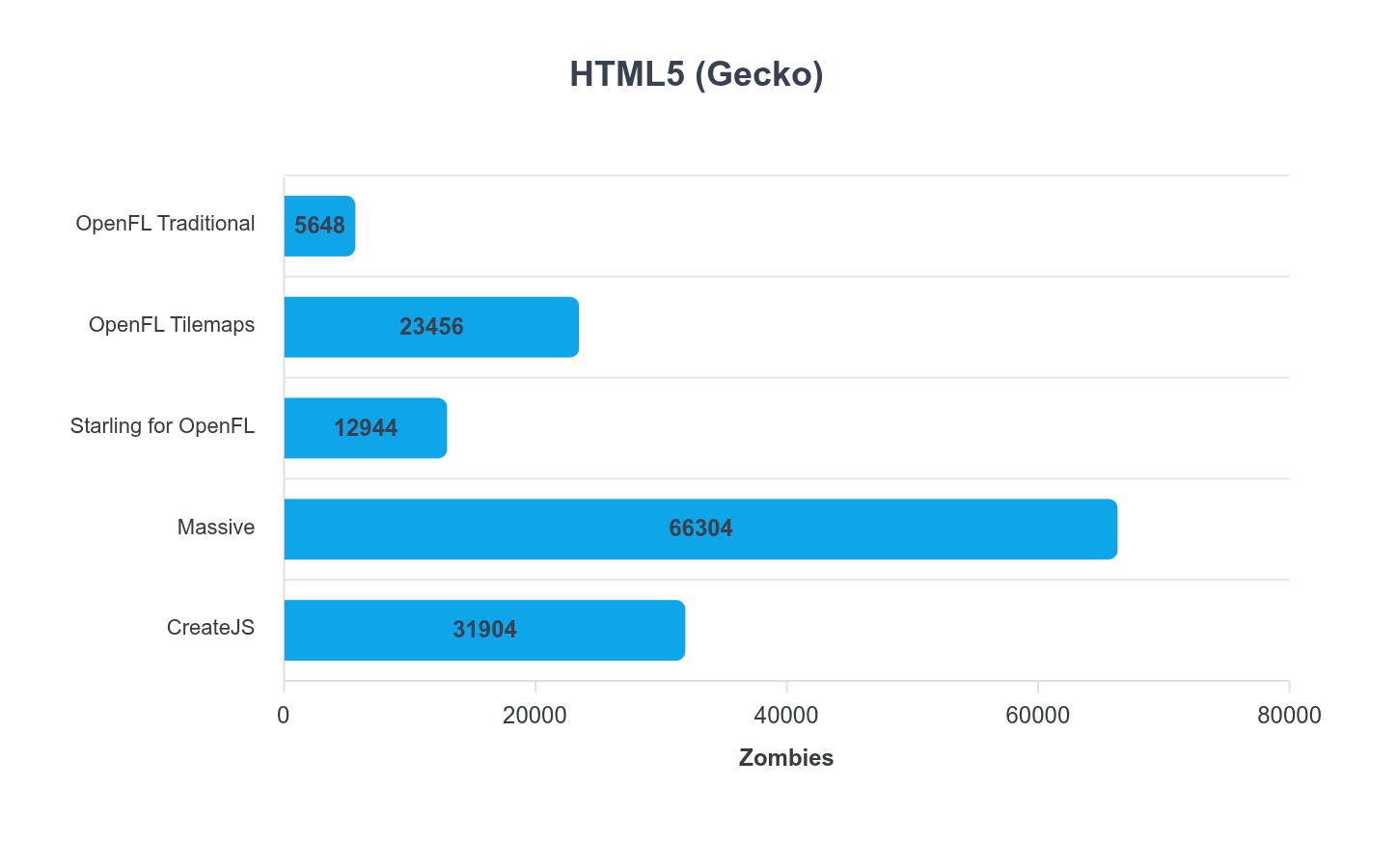
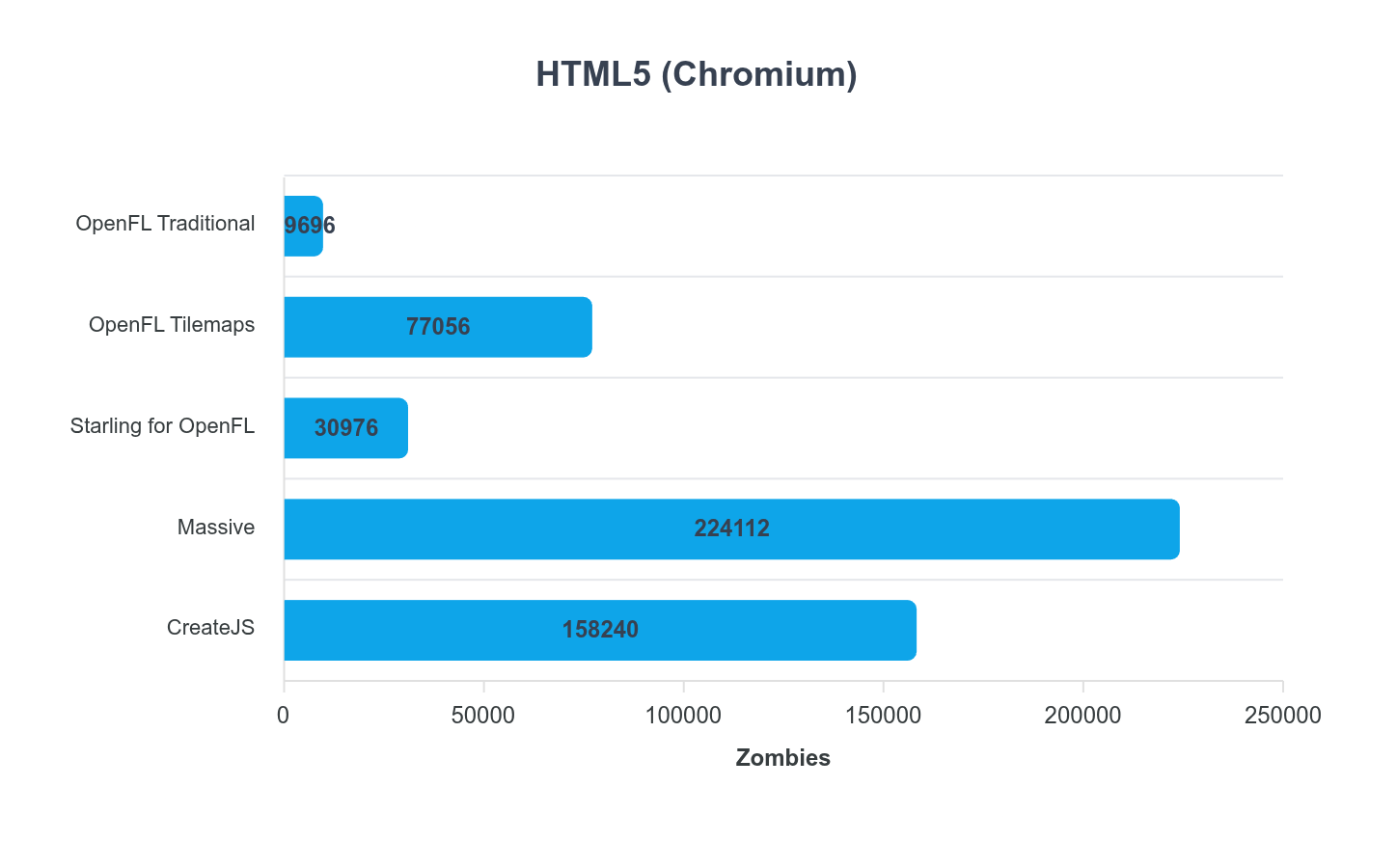
OpenFL “Traditional” is using the traditional Flash/AIR API style display list.
OpenFL “Tilemaps” uses Tilemaps (obviously). The performance here was impressive!
Starling didn’t perform as well as I might have expected, so this was eye opening. I spent quite a bit of time trying to squeeze it, but wasn’t able to improve the result.
Massive, well, @Matse these results are impressive!!!
HTML5 “Gecko” is tested in a Firefox based browser. The performance was consistently less than Chromium.
HTML5 “Chromium” is tested in a Chromium based browser.
Massive really stood out here! Amazing work @Matse!
The other thing I noted with @Matse’s Massive framework, is it wasn’t hindered by the display list style batching of OpenFL and Starling. It uses a unified MassiveDisplay container where that traditional hierarchy isn’t present.
I wanted to do that kind of benchmark, those are very interesting results with regular Starling being a lot more performant than regular OpenFL (even with its current “flaws”, I mean it could run much faster)
I would have been sad if Massive didn’t come on top It’s totally expected though : Massive is “cheating” here. I have a new version coming very soon, with skewing, color offsetting, program caching and improved performance
I submitted a PR to test this example, but the performance may not be very good. But I am happy to test it in order to optimize hxmaker! Please help me test again when there is a chance, thank you!
Updating the latest hxmaker and hxmaker openfl should be able to skip some unnecessary dependency libraries.
If you have any further questions, please let me know.
It’s not surprising that using Sprite as a renderer wastes a lot of performance when processing vertex data. I’ve always wanted to skip it, but I haven’t come up with a good way to improve it yet.
I will find a way to solve it tomorrow! i go to sleep now.
Thanks for sharing this. I’m playing around with a branch that modifies Starling’s VertexData and IndexData to use typed arrays instead of ByteArray, and this should be very helpful for making comparisons.
If there are issues and solutions you’re aware of, you might consider creating a pull request, or sharing your proposed solution here (given you’ve had difficulty accessing GitHub).
No, I don’t have a solution for “starling” performance improvement,
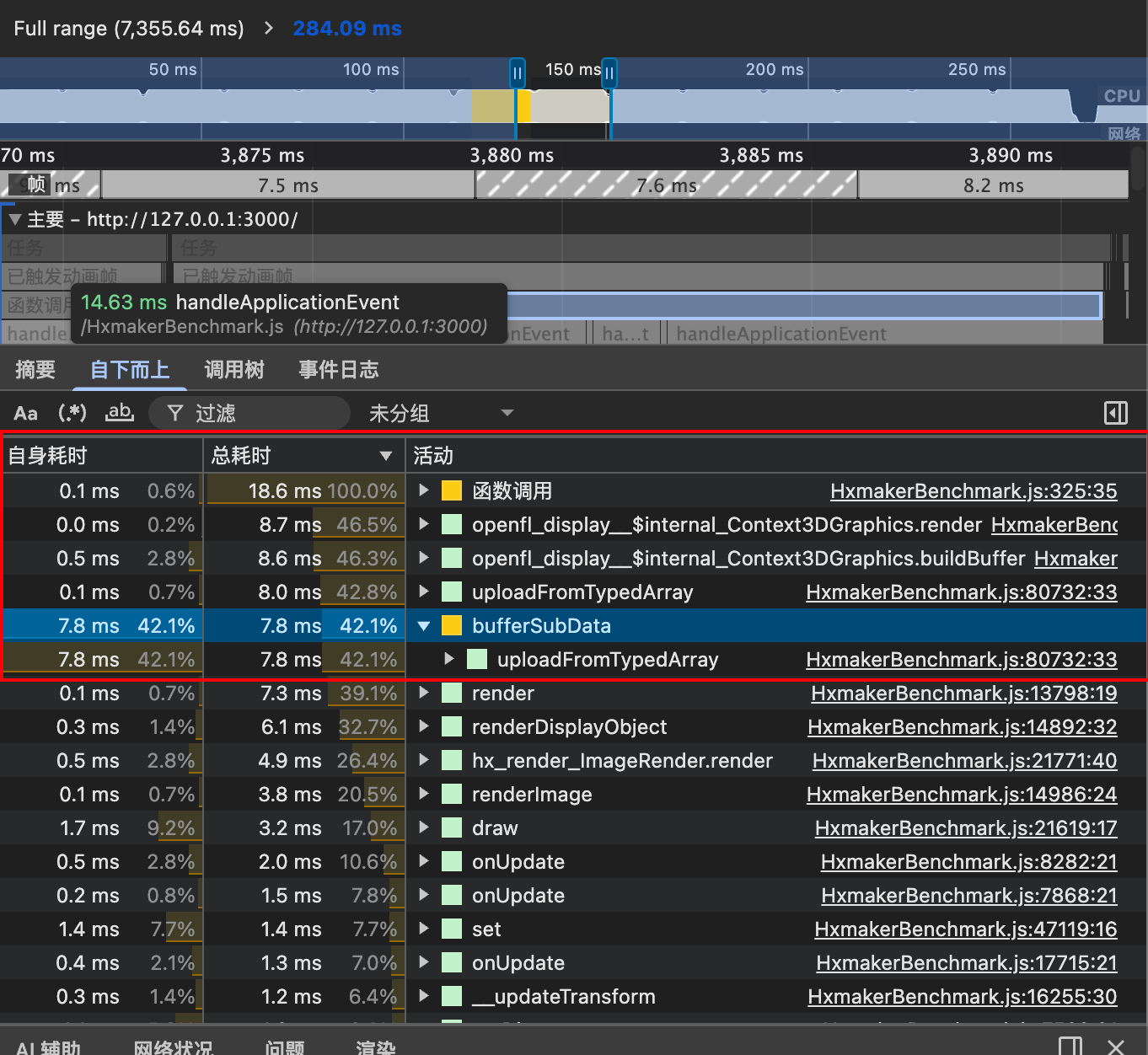
However, I would like to share my discovery that the “MovieClip” of “hxmaker” uses “array to save textures”, and from testing, the “moveclip” performance of “hxmaker” is higher than that of “starling”.
Does’ starling ‘use’ ByteArray 'to upload textures,
As far as I know, ByteArray is very slow. I was wondering if uploading textures using Array would be much faster?
I’ve pushed my changes to the upload-from-typed-array branch in my GitHub fork of Starling, so that folks can try it out. In this branch, both VertexData and IndexData use typed arrays by default.
You can define starling_force_upload_byte_array to restore the old behavior. I played around with an idea where if the rawData getter is called at run-time, it will switch to ByteArray mode automatically for maximum compatibility with any existing code that might access rawData (which seems to be strongly discouraged by the docs, actually). However, the code ended up being a little messier to support that, and I decided to start with something cleaner for testing.
All unit tests are passing with these changes. They did not need to be modified in any way.
Most targets have a nice increase in performance. Some better than others. On my machine, html5 is about 17% faster. C++ is 37% faster. Interestingly, HashLink (including both HL/JIT and HL/C) has the most dramatic improvement, being able to render 2.39x as many objects in Bink’s benchmarks. My theory is that hxcpp and browsers have much better garbage collectors that they deal with temporary objects better than HashLink’s GC.
I also made a more traditional BunnyMark sample for Starling locally, and HashLink/C is actually rendering more bunnies than hxcpp on that one, which feels weird.
Anyway, I need to work on other things now, but I hope that folks can give it a try and maybe offer further improvements.
For reference, I’ve been testing on Fedora Linux 43. I haven’t yet tried this code on Windows or macOS (or iOS or Android, for that mattter), so I don’t know how dramatic the difference will be there, whether better or worse than what I’m seeing.
I incorrectly assumed that HL/C would be close to, but maybe a tiny bit slower than, hxcpp. However, I was surprised to see that HL/C was running significantly faster than hxcpp on my Starling version of BunnyMark. And it’s bit faster, but only a little, in Bink’s benchmark.
These days, it should be just as easy as running this command:
I think C and C++ are pretty comparable, in terms of performance. It’s likely that some parts of C++ may have additional bottlenecks, but I’d guess core C++ stuff like classes aren’t adding significant overhead, if any.
Both hxcpp and HashLink implement their own small “runtime” on top of C and C++, though. The Haxe standard library, a garbage collector, etc. It was less that I thought that there’d be a difference in the C and C++ languages, and more that I expected these “runtimes” to have different characteristics. hxcpp is used by more people in production than HL/C. I think that HL/C is mostly used by Shiro, but fewer other companies because it wasn’t well documented how to set things up (at least until I implemented the hlc target in Lime). So I figured that hxcpp might be more optimized thanks to more real-world use.
HashLink/C hasn’t really been on my radar… and perhaps it should have been, particularly if it’s what Shiro leverage.
I look forward to giving your Starling branch a go @joshtynjala Thanks for putting work into that! I have a busy week this week, so I may not get to it for a bit unfortunately.